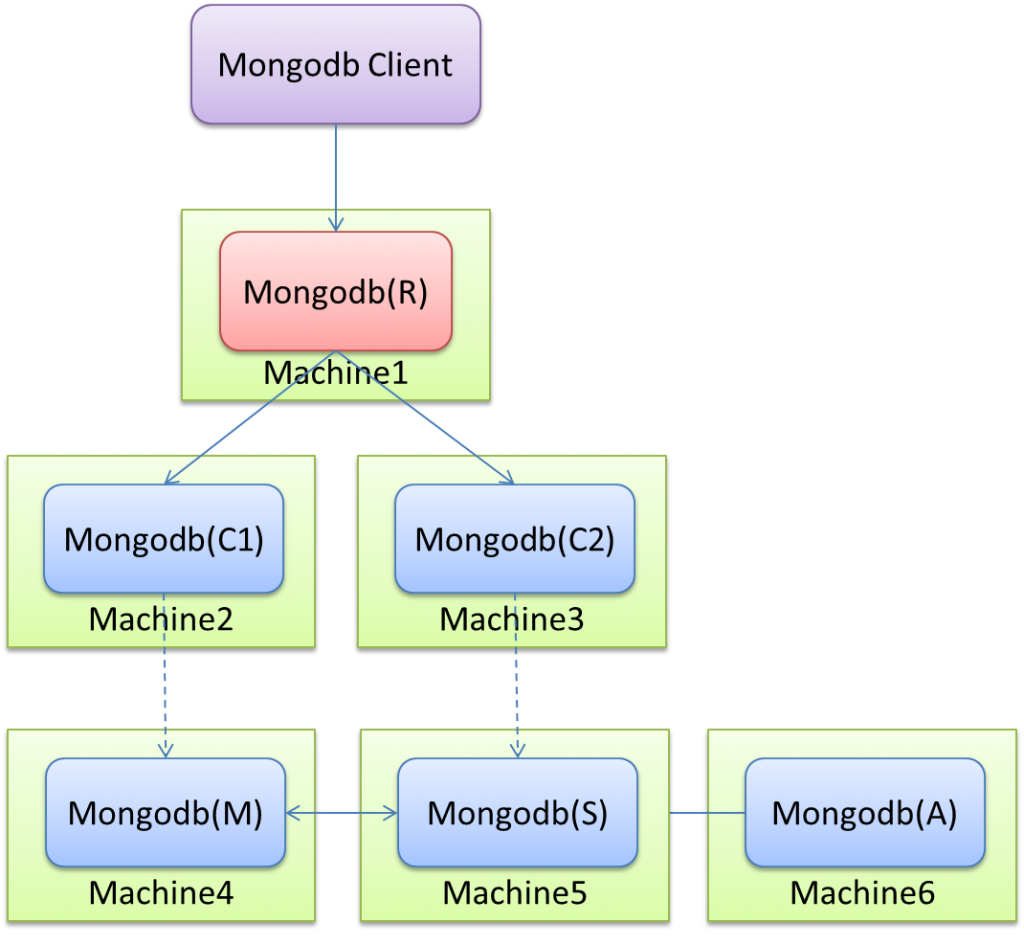
副本集
MongoDB中的一个副本集是保持相同数据集的一组mongod进程。副本集提供冗余和高可用性,并且是所有生产部署的基础。
1. 冗余和数据可用性
副本集提供冗余并增加数据可用性。在不同数据库服务器上具有多个数据副本时,副本集可以提供一个级别的单一数据库服务器丢失的容错能力。
在某些情况下,副本集可以提供增加的读取容量,因为客户端可以向不同的服务器发送读取操作维护不同数据中心的数据副本可以增加分布式应用程序的数据位置和可用性。还可以为专用目的维护其他副本,例如灾难恢复,报告或备份。
2. MongoDB中的副本集
副本集是保持相同数据集的一组mongod实例。副本集包含几个数据承载节点和可选的一个仲裁节点。在承载节点中,只有一个成员被认为是主节点,而其他节点被认为是次节点。
主节点接收所有写操作。主节点对数据集所有的操作记录都会在日志里,也就是oplog。

从节点复制主节点的日志,并将这些操作应用于其数据集,以便从节点数据集映射主节点。 如果主要节点不可用,合格的从节点将举行选举来选举新的主节点。

可以向副本集添加一个额外的mongod实例作为仲裁节点。仲裁节点不保留数据集。仲裁节点的目的是通过响应其他副本集成员的心跳和选举请求来维护副本集中的法定人数。因为它们不存储数据集,所以与具有数据集的完全功能的副本集成员相比,仲裁节点可以是以更便宜的资源成本提供副本集仲裁功能的好方法。如果您的副本组成员数量相当,则添加一个仲裁节点以获得大部分选票。仲裁节点不需要专用硬件。

仲裁节点永远都是仲裁节点,而通过选举,主节点可以成为次节点,次节点可以成为主节点。
3. 异步复制
次要应用主要异步的操作。通过在主要之后应用操作,即使一个或多个成员失败,集也可以继续运行。
4. 自动故障转移
当一个主节点不与该组其他成员沟通超过10秒钟时,合格的次节点将举行选举,选举新的主节点。举行选举和获得大多数议员选票的第一个次节点将成为主节点。

故障转移过程通常在一分钟内完成。例如,副本集的成员可能需要10-30秒才能声明主节点不可用(参见electionTimeoutMillis)。其余的次节点选举自己选为新的主节点可能需要10-30秒。
5. 读操作
默认情况下,客户端从主节点读取;然而,客户端可以指定读取首选项以将读取操作发送到次节点。 次节点的异步复制意味着从次节点读取返回的数据没有映射主节点数据的状态。
在MongoDB中,客户端可以在写入持久之前看到写入的结果:
- 无论写入问题,使用“本地”(即默认)readConcern的其他客户端可以在向发出客户端确认写入操作之前看到写入操作的结果。
- 使用“local”(即默认值)readConcern的客户端可以读取可能随后回滚的数据。
6. 附加功能
副本集提供了许多选项来支持应用程序需求。例如,可以在多个数据中心部署一个包含成员的副本集,或通过调整某些成员的成员来控制选举结果。副本集还支持报告,灾难恢复或备份功能的专用成员。
分片
分片是一种在多台机器间分配数据的方法。 MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署。
具有大数据集或高吞吐量应用程序的数据库系统可能会挑战单个服务器的容量。例如,高查询率可能会耗尽服务器的CPU容量。大于系统RAM的工作集大小会影响磁盘驱动器的I / O容量。
解决系统增长有两种方法:垂直和水平缩放。
垂直缩放涉及增加单个服务器的容量,例如使用更强大的CPU,增加更多的RAM或增加存储空间。可用的技术局限性可能会导致给定工作负载的单个机器不够强大。此外,基于云的提供商将根据可用的硬件配置进行硬顶。因此,垂直缩放有限。
水平缩放涉及将系统数据集和负载划分到多个服务器上,增加额外的服务器来根据需要增加容量。虽然单台机器的整体速度或容量可能不高,但每台机器处理整个工作负载的一部分,可能提供比单个高速大容量服务器更好的效率。扩展部署容量只需要根据需要增加额外的服务器,这可能比单个机器的高端硬件要低。
MongoDB支持通过分片进行横向缩放。
1. 分片集群
MongoDB分片集群由以下组件组成:
分片:每个分片包含分片数据的一部分。每个分片可以部署为副本集。
mongos:mongos作为查询路由器,提供客户端应用程序和分片集群之间的接口。
配置服务器:配置服务器存储集群的元数据和配置设置。从MongoDB 3.4开始,配置服务器必须部署为副本集(CSRS)。
以下图形描述了分片集群中组件的交互:
 MongoDB将集合级别的数据分片,将集合数据分布在集群中的分片上。
MongoDB将集合级别的数据分片,将集合数据分布在集群中的分片上。
2. 分片key
为了将文档分发到一个集合中,MongoDB使用分片对集合进行分区。分片key由不可变字段或目标集合中每个文档中存在的字段组成。
选择分片key对集合进行分片。分片后的分片key的选择不能改变。分片集合只能有一个分片key。
对一个非空集合分片,集合必须有以分片key为开头的索引。对于空集合,如果集合尚未具有指定分片key的适当索引,则MongoDB将创建索引。
分片key的选择会影响分片集群的性能,效率和可扩展性。具有最佳硬件和基础设施的集群可能会因为选择分片key而带来瓶颈。分片key及其后备索引的选择也会影响集群使用的分片策略。
3. 块
MongoDB将分片数据分割成块。每个块基于分片key都有一个包含较低和独占范围。
MongoDB使用划分集群平衡器在分片集群中的分片之间迁移块。平衡器试图在群集中的所有分片上实现均匀的块。
4. 分片优点
读写
MongoDB将读写工作负载分布在分片集群中的分片上,从而允许每个分片处理集群操作的一个子集。通过添加更多的分片,可以跨集群水平地缩放读取和写入工作负载。
对于包含分片key或复合分片key的前缀的查询,mongos可以以特定的分片或一组分片为目标查询。这些有针对性的操作通常比对群集中每个分片的广播效率更高。
存储容量
分片通过集群中的分片分发数据,从而允许每个分片包含总集群数据的子集。随着数据集的增长,其他分片增加了集群的存储容量。
高可用性
分片集群可以继续执行部分读/写操作,即使一个或多个分片不可用。虽然在停机期间无法访问不可用的分片上的数据子集,但是可用分片上的读取或写入仍然可以成功。
从MongoDB 3.2开始,可以将配置服务器部署为副本集。只要大部分副本集可用,带有配置服务器副本集(CSRS)的分片集群可以继续处理读取和写入。在3.4版本中,MongoDB删除了对SCCC配置服务器的支持。要将配置服务器从SCCC升级到CSRS。
在生产环境中,应将各个分片部署为副本集,从而提供更多的冗余和可用性。
5. 分片前注意事项
分片群集的基础架构要求和复杂性需要仔细的规划,执行和维护。
为确保集群性能和效率,必须认真考虑选择分片key。分片后不能更改分片key,也不能取消一个分片的集合。
分片具有一定的操作要求和限制。
如果查询不包括分片key或复合分片key的前缀,则mongos会执行广播操作,查询分片集群中的所有分片。这些分散/聚合的查询可以是长时间运行的操作。
6. 分片和未分片集合
数据库可以混合使用分片和未分片的集合。分片集合被分区并分布在集群中的分片上。未分片的集合存储在主分片上。每个数据库都有自己的主分片。

7. 连接到分片集群
必须连接到mongos路由器才能与分片集群中的任何集合进行交互。这包括分片和未分片的集合。为了执行读写操作,客户端不应连接到单个分片。

您可以通过连接到mongod的方式连接到一个mongos,例如通过mongo shell或MongoDB驱动程序
8. 分片策略
MongoDB支持两种分片策略,用于在分片集群中分配数据。
哈希分片
哈希分片涉及计算分片key字段值的哈希值。然后,基于分片key的哈希值为每一个块分配一个范围。 当使用散列索引解析查询时,MongoDB会自动计算哈希值。应用程序不需要计算哈希值。

虽然一系列分片key可能“close”,但它们的散列值不大可能在同一块。基于哈希值的数据分布有助于更均匀的数据分布,特别是在分片key单调变化的数据集中。
然而,散列分布意味着在分片key上的基于范围的查询不太可能针对单个分片,导致更多的群集广播操作。
远程分片
远程分片包括基于分片key的值将数据划分范围。然后根据分片key值为每一个块分配一个范围。

分片key值为’close’的更可能驻留在相同的块上。这样就允许目标操作通过mongos将操作路由到仅包含所需数据的分片。
远程分片的效率取决于所选择的分片key。数据分配不佳可能导致数据分布不均匀,这可能会抵消分片的一些好处,也可能导致性能瓶颈。
9. 分片集群中的区域
在分片集群中,您可以基于分片key创建分片数据区域。可以将每个区域与集群中的一个或多个分片相关联。分片可以与任何数量的非冲突区域相关联。在平衡群集中,MongoDB将区域覆盖的块仅迁移到与区域相关联的分片。
每个区域覆盖一个或多个分片键值范围。区域覆盖的每个范围总是包含其下边界,不包括其上边界。

在定义要覆盖的区域的新范围时,必须使用分片key中包含的字段。如果使用复合分片键,则范围必须包含分片键的前缀。
选择分片key时,需要仔细考虑以后使用区域划分的可能性,因为在集合分片后无法更改分片key。
最常见的是,区域可以改善跨越多个数据中心的分片集群的数据位置。
10. 分片中的排序
使用shardCollection命令与排序规则:{locale:“simple”}选项分隔具有默认排序规则的集合。成功的分片要求:
- 该集合必须具有前缀为分片键的索引
- 索引必须具有排序规则{locale:“simple”} 在使用归类创建新集合时,请确保在分片集合之前满足这些条件。
备注: 分片集合上的查询继续使用为集合配置的默认排序规则。要使用分片键索引的简单归类,在查询的排序规则文档中指定{locale:“simple”}。
11. 其他资源
Mongodb集群搭建的三种方式
1. 主从模式
官方已经不推荐这种方式,简单介绍下。

#进入mongodb的bin目录下
cd /Users/nanfang/2017/mongdb-demo/mongodb-osx-x86_64-3.4.6/bin
#主节点
./mongod -f /Users/nanfang/2017/mongdb-demo/master-slave/conf/master.conf -master
./mongod --master --dbpath /Users/nanfang/2017/mongdb-demo/master-slave
#从节点
./mongod -slave -source 192.168.119.238:27018 -f /Users/nanfang/2017/mongdb-demo/master-slave/conf/slaver.conf
./mongod --slave --source <masterip:masterport> --dbpath /Users/nanfang/2017/mongdb-demo/master-slave/data/slavedb
./mongod –slave –source 127.0.0.1:27017 –dbpath /Users/nanfang/2017/mongdb-demo/master-slave/data/slavedb
 主节点日志输出
主节点日志输出
#成功
2017-08-09T14:37:10.071+0800 I CONTROL [initandlisten] MongoDB starting : pid=9168 port=27018 dbpath=/Users/nanfang/2017/mongdb-demo/master-slave/data/master master=1 64-bit host=pengnanfangdeMacBook-Pro.local
...
2017-08-09T14:37:11.188+0800 I NETWORK [thread1] waiting for connections on port 27018
从节点日志输出
#成功
2017-08-09T14:39:53.576+0800 I CONTROL [initandlisten] MongoDB starting : pid=9217 port=27019 dbpath=/Users/nanfang/2017/mongdb-demo/master-slave/data/slaver slave=1 64-bit host=pengnanfangdeMacBook-Pro.local
...
2017-08-09T14:39:54.435+0800 I NETWORK [thread1] waiting for connections on port 27019
#同步
2017-08-09T14:39:55.615+0800 I REPL [replslave] syncing from host:192.168.119.238:27018
2017-08-09T14:39:56.618+0800 I REPL [replslave] sleep 2 sec before next pass
2017-08-09T14:39:58.621+0800 I REPL [replslave] syncing from host:192.168.119.238:27018
2017-08-09T14:39:59.627+0800 I REPL [replslave] syncing from host:192.168.119.238:27018
测试主从复制
在主节点上连接到终端:
> use test;
switched to db test
> db.testdb.insert({"test1":"testval1"})
WriteResult({ "nInserted" : 1 })
> db.testdb.find();
{ "_id" : ObjectId("598ab03a422ba64b43e7ae48"), "test1" : "testval1" }
主机同步日志
2017-08-09T14:47:55.940+0800 I NETWORK [thread1] connection accepted from 192.168.119.238:60270 #7 (2 connections now open)
查看从节点
> show dbs;
2017-08-09T14:51:48.485+0800 E QUERY [thread1] Error: listDatabases failed:{
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk"
} :
_getErrorWithCode@src/mongo/shell/utils.js:25:13
Mongo.prototype.getDBs@src/mongo/shell/mongo.js:62:1
shellHelper.show@src/mongo/shell/utils.js:769:19
shellHelper@src/mongo/shell/utils.js:659:15
@(shellhelp2):1:1
解决方案 在主库上设置 slaveok=ok 执行 db.getMongo().setSlaveOk(); 从库上执行 rs.slaveOk();
> show dbs;
admin 0.000GB
local 0.000GB
test 0.000GB
> use test;
switched to db test
> db.testdb.find();
{ "_id" : ObjectId("598ab03a422ba64b43e7ae48"), "test1" : "testval1" }
故障转移测试
a. 测试从节点是否可以当成主节点
> db.testdb.insert({"test2":"testval2"});
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
b. 模拟主节点挂掉,从节点是否自动变为可写 kill主节点 从节点日志
2017-08-09T15:03:40.564+0800 I REPL [replslave] AssertionException 10278 dbclient error communicating with server: 192.168.119.238:27018
2017-08-09T15:03:40.564+0800 I - [replslave] caught exception (socket exception [FAILED_STATE] for 192.168.119.238:27018 (192.168.119.238) failed) in destructor (kill)
2017-08-09T15:03:40.564+0800 I REPL [replslave] sleep 2 sec before next pass
2017-08-09T15:03:42.569+0800 I REPL [replslave] syncing from host:192.168.119.238:27018
2017-08-09T15:03:42.569+0800 W NETWORK [replslave] Failed to connect to 192.168.119.238:27018, in(checking socket for error after poll), reason: Connection refused
2017-08-09T15:03:42.569+0800 E REPL [replslave] couldn't connect to server 192.168.119.238:27018, connection attempt failed
2017-08-09T15:03:42.569+0800 I REPL [replslave] sleep 3 sec before next pass
2017-08-09T15:03:45.571+0800 I REPL [replslave] syncing from host:192.168.119.238:27018
2017-08-09T15:03:45.574+0800 W NETWORK [replslave] Failed to connect to 192.168.119.238:27018, in(checking socket for error after poll), reason: Connection refused
从节点是否自动可写
> db.testdb.insert({"test2":"testval2"});
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
不能,需要手工停止从节点后将该节点标识为主节点
2. Replica Set(副本集)
简单来说就是集群当中包含了多份数据,保证主节点挂掉了,备节点能继续提供数据服务,提供的前提就是数据需要和主节点一致。如下图:
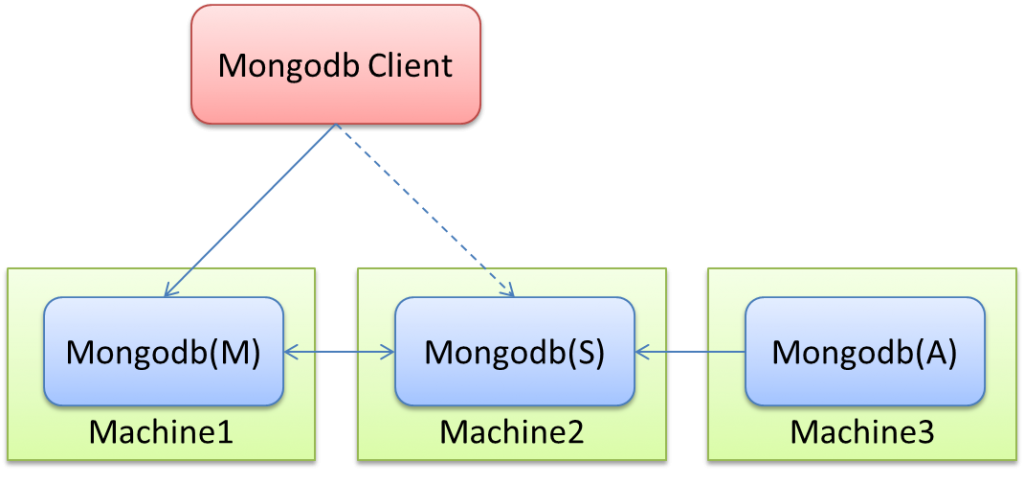
集群方案
Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。 默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。 仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
搭建
1. 建立数据文件夹
三个目录分别对应主,备,仲裁节点
mkdir -p ~/mongodb-demo/data/master
mkdir -p ~/mongodb-demo/data/slaver
mkdir -p ~/mongodb-demo/data/arbiter
2. 建立配置文件
#以主节点为例
#master.conf
dbpath=/Users/nanfang/2017/mongdb-demo/cluster/data/master
logpath=/Users/nanfang/2017/mongdb-demo/cluster/log/master.log
pidfilepath=/Users/nanfang/2017/mongdb-demo/cluster/master.pid
directoryperdb=true
logappend=true
replSet=testrs
bind_ip=192.168.119.238
port=27018
oplogSize=10000
fork=true
noprealloc=true
参数解释: dbpath:数据存放目录 logpath:日志存放路径 pidfilepath:进程文件,方便停止mongodb directoryperdb:为每一个数据库按照数据库名建立文件夹存放 logappend:以追加的方式记录日志 replSet:replica set的名字 bind_ip:mongodb所绑定的ip地址 port:mongodb进程所使用的端口号,默认为27017 oplogSize:mongodb操作日志文件的最大大小。单位为Mb,默认为硬盘剩余空间的5% fork:以后台方式运行进程 noprealloc:不预先分配存储
3. 启动mongodb
#进入每个mongodb节点的bin目录下
cd /Users/nanfang/2017/mongdb-demo/mongodb-osx-x86_64-3.4.6/bin
#主节点
./mongod -f /Users/nanfang/2017/mongdb-demo/cluster/conf/master.conf
#从节点
./mongod -f /Users/nanfang/2017/mongdb-demo/cluster/conf/slaver.conf
#备节点
./mongod -f /Users/nanfang/2017/mongdb-demo/cluster/conf/arbiter.conf
4. 配置主,备,仲裁节点
可以通过客户端连接mongodb,也可以直接在三个节点中选择一个连接mongodb
> rs.status()
{
"info" : "run rs.initiate(...) if not yet done for the set",
"ok" : 0,
"errmsg" : "no replset config has been received",
"code" : 94,
"codeName" : "NotYetInitialized"
}
> use admin
switched to db admin
> cfg={ _id:"testrs", members:[ {_id:0,host:'192.168.119.238:27018',priority:2}, {_id:1,host:'192.168.119.238:27019',priority:1},
... {_id:2,host:'192.168.119.238:27020',arbiterOnly:true}] };
{
"_id" : "testrs",
"members" : [
{
"_id" : 0,
"host" : "192.168.119.238:27018",
"priority" : 2
},
{
"_id" : 1,
"host" : "192.168.119.238:27019",
"priority" : 1
},
{
"_id" : 2,
"host" : "192.168.119.238:27020",
"arbiterOnly" : true
}
]
}
> db.testdb.insert({"test1":"testval1"}) #配置还未生效
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
> use test
switched to db test
> db.testdb.insert({"test1":"testval1"})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
> rs.initiate(cfg) #使配置生效
{ "ok" : 1 }
testrs:SECONDARY>
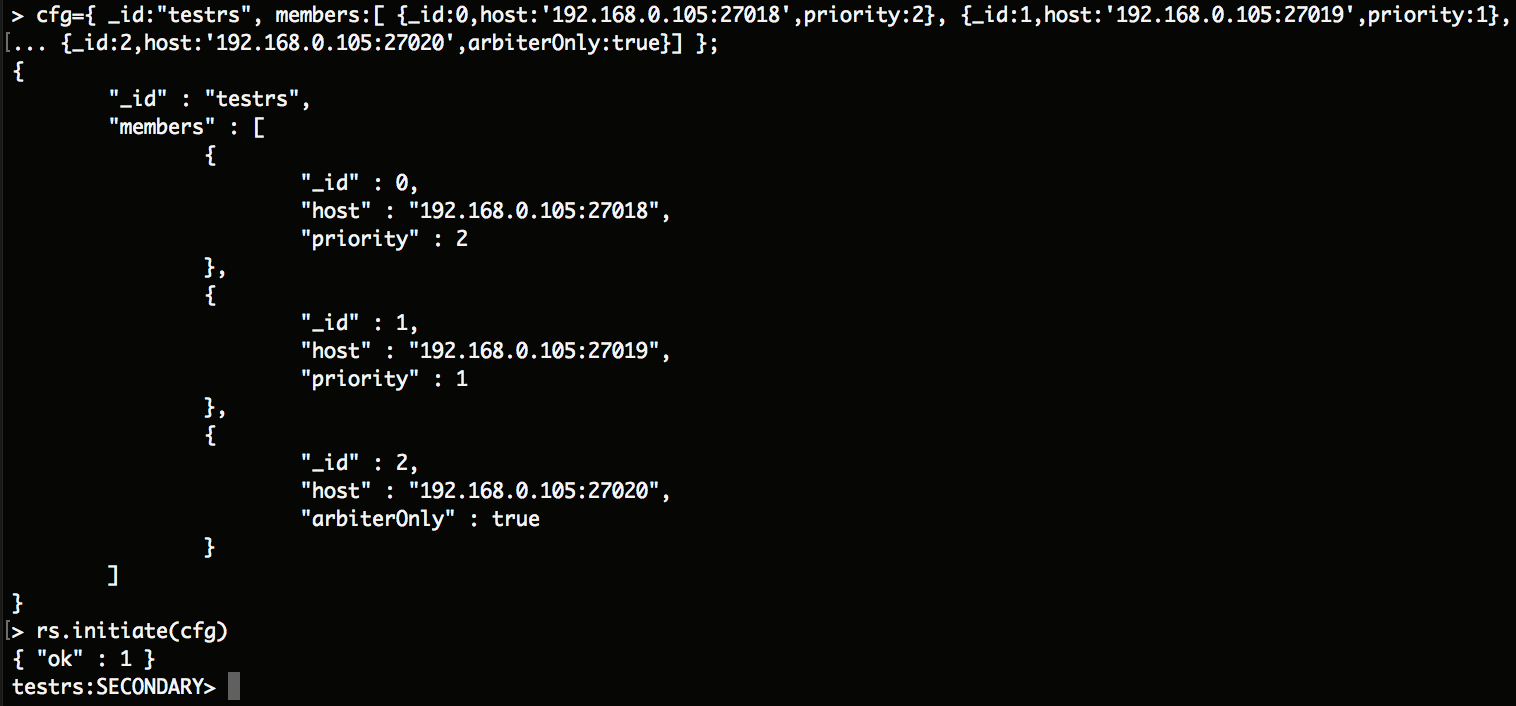
测试
1. 查看集群状态
rs.status()
2. 往主节点插入数据,能从备节点查到之前插入的数据
同主从复制
3. 停掉主节点,从节点能变成主节点提供服务
a. 先测试从节点是否可写
testrs:SECONDARY> db.testdb.insert({"test2":"testval2"})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })
testrs:SECONDARY>
b. 主节点挂掉 主节点状态(not reachable/healthy) 从节点状态PRIMARY
#从节点日志
2017-08-09T15:32:52.216+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to 192.168.119.238:27018
2017-08-09T15:32:52.217+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Failed to connect to 192.168.119.238:27018 - HostUnreachable: Connection refused
2017-08-09T15:32:52.217+0800 I ASIO [NetworkInterfaceASIO-Replication-0] Dropping all pooled connections to 192.168.119.238:27018 due to failed operation on a connection
2017-08-09T15:32:52.217+0800 I REPL [ReplicationExecutor] Error in heartbeat request to 192.168.119.238:27018; HostUnreachable: Connection refused
测试从节点是否可写
testrs:SECONDARY> db.testdb.insert({"test2":"testval2"})
WriteResult({ "nInserted" : 1 })
4. 恢复主节点,备节点也能恢复其备的角色,而不是继续充当主的角色
从主从日志中以及rs.status()看出 主节点恢复,备节点也能恢复其备的角色,而不是继续充当主的角色
3. 分片
概念
分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。通过一个名为mongos的路由进程进行操作,mongos知道数据和片的对应关系(通过配置服务器)。大部分使用场景都是解决磁盘空间的问题,对于写入有可能会变差(+++里面的说明+++),查询则尽量避免跨分片查询。使用分片的时机:
- 机器的磁盘不够用了。使用分片解决磁盘空间的问题。
- 单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源。
- 想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源。
搭建
分片中各个角色的作用: ① 配置服务器。是一个独立的mongod进程,保存集群和分片的元数据,即各分片包含了哪些数据的信息。最先开始建立,启用日志功能。像启动普通的mongod一样启动配置服务器,指定configsvr选项。不需要太多的空间和资源,配置服务器的1KB空间相当于真是数据的200MB。保存的只是数据的分布表。当服务不可用,则变成只读,无法分块、迁移数据。 ② 路由服务器。即mongos,起到一个路由的功能,供程序连接。本身不保存数据,在启动时从配置服务器加载集群信息,开启mongos进程需要知道配置服务器的地址,指定configdb选项。 ③ 分片服务器。是一个独立普通的mongod进程,保存数据信息。可以是一个副本集也可以是单独的一台服务器。
1. 环境
A:配置(3)、路由1、分片1;
B:分片2,路由2;
C:分片3
片键: 片键必须是一个索引,数据根据这个片键进行拆分分散。通过sh.shardCollection加会自动创建索引。一个自增的片键对写入和数据均匀分布就不是很好,因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。在所有分片上查询,mongos会对结果进行归并排序。
2. 配置服务器的启动。(A上开启3个,Port:20000、21000、22000)
配置服务器是一个普通的mongod进程,所以只需要新开一个实例即可。配置服务器必须开启1个或则3个,开启2个则会报错:
BadValue need either 1 or 3 configdbs
配置文件
#config_1.conf
#数据目录
dbpath=/Users/nanfang/2017/mongdb-demo/sharding/data/config1
#日志文件
logpath=/Users/nanfang/2017/mongdb-demo/sharding/log/config1.log
#日志追加
logappend=true
#端口
port = 27021
#最大连接数
maxConns = 50
pidfilepath = /Users/nanfang/2017/mongdb-demo/sharding/config1.pid
#日志,redo log
journal = true
#刷写提交机制
journalCommitInterval = 200
#守护进程模式
fork = true
#刷写数据到日志的频率
syncdelay = 60
#storageEngine = wiredTiger
#操作日志,单位M
oplogSize = 1000
#命名空间的文件大小,默认16M,最大2G。
nssize = 16
noauth = true
unixSocketPrefix = /tmp
configsvr = true
cd /Users/nanfang/2017/mongdb-demo/mongodb-osx-x86_64-3.4.6/bin
./mongod -f /Users/nanfang/2017/mongdb-demo/sharding/conf/config_1.conf
./mongod -f /Users/nanfang/2017/mongdb-demo/sharding/conf/config_2.conf
./mongod -f /Users/nanfang/2017/mongdb-demo/sharding/conf/config_3.conf
注1: mongodb 3.4之后,虽然要求config server为replica set,但是不支持arbiter。添加的时候,会报错:
rs.initiate(cfg)
{
"ok" : 0,
"errmsg" : "Arbiters are not allowed in replica set configurations being used for config servers",
"code" : 93,
"codeName" : "InvalidReplicaSetConfig"
}
2. 路由服务器的启动。(A、B上各开启1个,Port:30000)
路由服务器不保存数据,把日志记录一下即可。
cd /Users/nanfang/2017/mongdb-demo/mongodb-osx-x86_64-3.4.6/bin
./mongos -configdb 192.168.119.238:27021,192.168.119.238:27022,192.168.119.238:27023 -port 27024 -f /Users/nanfang/2017/mongdb-demo/sharding/conf/route1.conf
mongos -f /Users/nanfang/2017/mongdb-demo/sharding/conf/route1.conf
和Replica Set类似,都需要一个仲裁节点,但是Sharding还需要配置节点和路由节点。就三种集群搭建方式来说,这种是最复杂的。部署图如下: